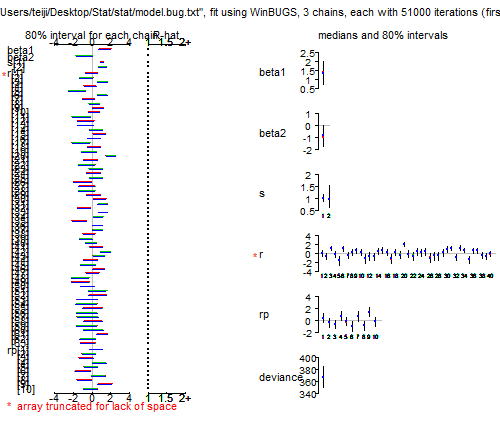
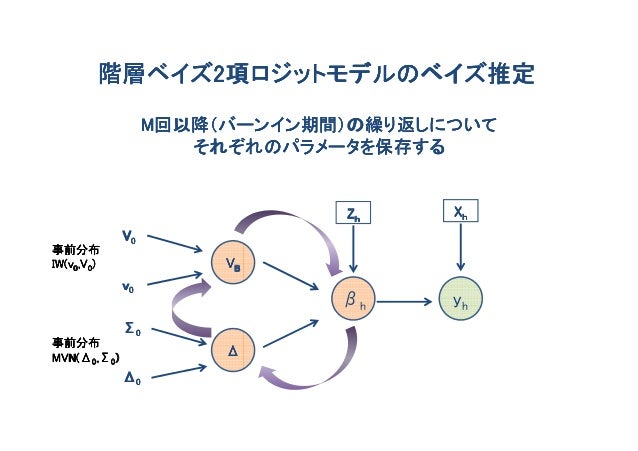
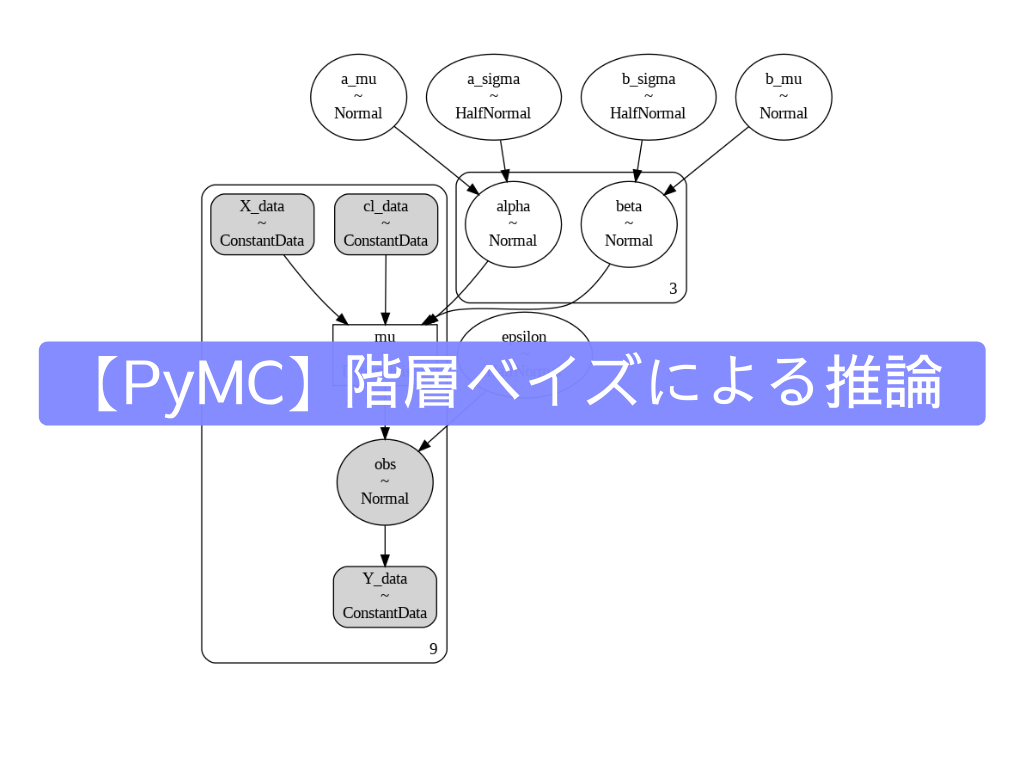
階層ベイズモデル(かいそうべいずもでる、Bayesian hierarchical modeling)は、複数のレベルで記述された、階層形式の統計モデルであり、ベイズ推定を用いて事後分布のパラメータを推定する。サブモデルを組み合わせて階層的なモデルを形成し、ベイズの定理を用いて観測データと統合して、全ての不確実性を考慮した事後分布を得る。
ベイズ統計ではパラメータを確率変数として扱い、主観的な情報に基づき、これらのパラメータの分布を仮定する。このため、頻度論的統計ではベイズ統計とは一見矛楯した結論が得られることがある。設定する問い自体が異なるため厳密に言えば矛楯するものではないが、どちらの答えを重要視するかに違いがある。ベイジアンは、意思決定と信念の更新についての関連情報を無視することはできないこと、対象者から複数の観察データが得られる場合には階層モデリングが古典的な方法を覆す可能性があることを主張する。さらに、このモデルはロバストであることが証明されており、事後分布は、より柔軟な階層的事前分布にはあまり影響されない。
階層モデリングは、複数の異なるレベルの観測単位で情報が得られる場合に使用する。例えば、複数の国の感染経路を記述する疫学モデルでは、観測単位は国であり、国毎に日々の感染者の経時的データが異なる。複数の油田やガス田の産出量の減衰曲線を説明する減衰曲線分析では、観測単位は貯蔵地域の油田またはガス田であり、それぞれに生産率経時的データがある(通常、バレル/月) 。階層モデリングのデータ構造は入れ子状である。階層的な分析・統合は、パラメータがたくさんある問題を理解するのに役立つだけでなく、計算戦略の策定にも重要な役割を果たす。
基本原理
統計的手法とモデルは、一般に、問題がこれらのパラメータの同時確率モデルの依存性を暗示するような方法で関連または接続されていると見なすことができる複数のパラメータを含む。確率の形で表される個々の信念の程度には、不確実性が伴う。その中で、時間の経過とともに信念の度合いが変化する。ホセ・M・ベルナルド教授とエイドリアン・F・スミス教授が述べたように、「学習プロセスの現実は、現実についての個人的および主観的な信念の進化にある」。これらの主観的な確率は、物理的な確率よりも精神に直接関係している。したがって、ベイジアンが特定のイベントの事前発生を考慮に入れた代替の統計モデルを策定したのは、この信念を更新する必要があるためである。
ベイズの定理
現実世界で事象が発生した場合、通常、ある選択肢における選好が修正される。これは、選択肢を定義する事象に対して個人が抱く信念の度合いを修正することで行われる。
心臓治療の効果を調べる研究で、病院 の患者の生存確率を とする。生存確率 は、心臓病患者の生存率を高めると信じる人がいる事象 の発生で更新される。
イベント が発生した状況で、 について確率の記述を更新するには、 と の同時分布 を与えるモデルから始めなければならない。
これは、事前分布 とサンプリング分布 の積として記述することができる。
条件付き確率の基本性質から、事後分布は次のようになる。
この条件付き確率と個々の事象との関係を示す式をベイズの定理という。
この単純な表現の中に、更新された信念 を適切かつ解決可能な方法で組み込むことを目的とするベイズ推定の技術的核心が含まれている。
交換可能性
統計分析は、通常、 個の値 が交換可能であることを仮定することから始める。
を他と区別する情報がデータ しかなく、パラメータの順序付けやグループ化ができない場合、事前分布においてパラメータ間の対称性を仮定する必要がある。この対称性は、確率的には、交換可能性で表される。
一般的に、分布 に従うパラメーターベクトル が与えられたとき、独立同分布としてモデル化することが有用かつ適切である。
有限の交換可能性
定数 n に対して、集合 が交換可能であるとは、同時確率 が添え字の順列によらず不変であることをいう。つまり、 を並び替えて得られるすべての順列 に対して次の式が成立する。
が独立同分布ならば交換可能だが、交換可能であっても独立同分布であるとは限らない。
次に、交換可能だが独立同分布ではない例を示す。
壺の中に赤い玉 1 個と青い玉 1 個があり、二分の一の確率でどちらかを取り出すものとする。n 個の中から玉を 1 個取り出して、引いた玉は戻さずに、n - 1 個の中から次の玉を取り出す。
最初に赤い玉、2 番目に青い玉を取り出す確率も、最初に青い玉、2 番目に赤い玉を取り出す確率も、同じく二分の一であり、 と とは交換可能である。
しかし、最初に赤い玉を取り出した後で 2 番目に赤い玉を取り出す確率は 0 であり、2 回目に赤い玉を取り出す確率とは等しくない。
無限の交換可能性
無限の交換可能性とは、無限数列 のすべての有限な部分集合が交換可能である、という性質である。つまり、任意の について、数列 交換可能である。
階層モデル
構成要素
階層ベイズモデルでは、以下の 2 つの重要な概念を利用して事後分布を導出する。
- ハイパーパラメータ Hyperparameter:事前分布のパラメータ
- 超事前分布 Hyper prior:ハイパーパラメータの分布
確率変数 が、平均 、分散 1 の正規分布に従うと仮定する。このことを、チルダを用いて下記のように表記する。
さらに、パラメータ が平均 、分散 1 の正規分布に従うと仮定する。
そして、ハイパーパラメータ が標準正規分布に従うものとする。
このようなハイパーパラメータが従う分布を、超事前分布と呼ぶ。
の分布の表記は、別のパラメータを追加することで変化する。
ハイパーパラメータ が平均 分散 の正規分布に従う場合、 と もまたハイパーパラメータであり、その分布も超事前分布となる。
枠組み
を観測値、 を のデータ生成過程を支配するパラメータとする。
さらに、パラメータ が交換可能な形で共通母集団から生成され、その分布がハイパーパラメータ によって規定されるものとする。
階層ベイズモデルには、次の段階が含まれる。
- Stage I
- Stage II
- Stage III
尤度 は に依存するが、 は を通してのみ尤度に影響する。
条件付き確率の定義から、 の事前分布 は、超事前分布 を用いて、次のように分解できる。
ベイズの定理から、 の事後分布 は次のように比例する。
以上から、
例
このことをさらに説明するために、次のような例を考えてみる。ある教師が、生徒の SAT での成績を推定したいものとする。教師は、生徒の高校の成績と現在の GPA(評点平均)に関する情報を使って、推定値を算出する。生徒の現在の GPA を 、SAT の成績を として、次のように表される。
SAT の成績は、学年 でインデックスされた共通の母集団分布からのサンプルとみなされる。
さらに、ハイパーパラメータ は超事前分布 が与える分布に従う。
GPAに関する情報に基づいて SAT を予測するには、
問題のすべての情報が事後分布を解くために使用される。
事前分布と尤度関数だけを使って解くのではなく、超事前分布を使うことで、より多くの情報を得て、パラメータの振る舞いについてより正確な信念を持つことができる。
2段階の階層モデル
一般に、2段階の階層モデルで関心のある共同事後分布は次の通り。
3段階の階層モデル
3段階の階層モデルの場合、事後分布は次の式で与えられる。
脚注
出典
参考文献
- 久保拓弥『データ解析のための統計モデリング入門』岩波書店、2012年5月18日。ISBN 9784000069731。
関連項目